1. 基本概念
字符集(Character set):是一个系统支持的所有抽象字符的集合。字符是各种文字和符号的总称,包括各国家文字、标点符号、图形符号、数字等。常见的字符集有ASCII、ZHS16GBK 、ZHT16BIG5、 ZHS32GB18030字符集、Unicode字符集等。
字符编码(Character Encoding):是一套法则,使用该法则能够对自然语言的字符的一个集合(如字母表或音节表),与其它的一个集合(如电脑编码)进行配对。即在符号集合与数字系统之间建立对应关系。与字符集相对应,常见的字符编码有:ASCii,ZHS16GBK,ZHT16BIG5,ZHS32GB18030等。
字符集的定义其实就是字符的集合,而字符编码则是指怎么将这些字符变成字节用于保存、读取和传输。
2. 字符集的前世今生
1) 通用字符集UCS
通用字符集(Universal Character Set,UCS)是由ISO制定的ISO 10646(或称ISO/IEC 10646)标准所定义的字符编码方式,采用4字节编码。又称Universal Multiple-Octet Coded Character Set,大陆译为通用多八位编码字符集,台湾译为广用多八位元编码字元集。
通用字符集是所有包括了其他字符集。它保证了与其他字符集的双向兼容,即,如果你将任何文本字符串翻译到UCS格式,然后再翻译回原编码,你不会丢失任何信息。UCS包含了已知语言的所有字符。除了拉丁语、希腊语、斯拉夫语、希伯来语、阿拉伯语、亚美尼亚语、乔治亚语,还包括中文、日文、韩文这样的象形文字,UCS还包括大量的图形、印刷、数学、科学符号。
通用字符集是与UNICODE同类的组织,UCS-2和UNICODE兼容。
2) Unicode编码
Unicode(统一码、万国码、单一码)是一种在计算机上使用的字符编码。包含了几乎人类所有可用的字符,每年还在不断的增加,可以看作是一种通用的字符集。Unicode定义了大到足以代表人类所有可读字符的字符集。Java语言就用到了Unicode编码,从而实现了该语言的国际通用性。
Unicode 是基于通用字符集(Universal Character Set)的标准来发展, 用数字0-0x10FFFF来映射这些字符,或者说有1114112个码位(码位就是可以分配给字符的数字)。
对可以用ASCII表示的字符使用UNICODE并不高效,因为UNICODE比ASCII占用大一倍的空间,而对ASCII来说高字节的0对他毫无用处。为了解决这个问题,有人发明了一种针对UNICODE的变换规则,把UNICODE字符串中的0去除。 注意这个变换规则不是通过查表实现的,而只要用一些位移操作就可以实现。 这就是UTF,他们被称为通用转换格式,即UTF(UCS Transformation Format)。常见的UTF格式有:
UTF-32编码:固定使用4个字节来表示一个字符,这种编码存在空间利用效率的问题。
UTF-16编码:对相对常用的60000余个字符使用两个字节进行编码,其余的使用4字节。
UTF-8编码: 兼容ASCII编码;拉丁文、希腊文等使用两个字节;包括汉字在内的其它常用字符使用三个字节;剩下的极少使用的字符使用四个字节。
下面重点介绍下UTF-8编码:
UTF-8以字节为单位对Unicode进行编码。从Unicode到UTF-8的编码方式为:将Unicode二进制从低位往高位取出二进制数字,每次取6位,如上述的二进制就可以分别取出为如下示例所示的格式,前面按格式填补,不足8位用0填补。
| Unicode编码(16进制) | UTF-8 字节流(二进制) |
| 000000 - 00007F | 0xxxxxxx |
| 000080 - 0007FF | 110xxxxx 10xxxxxx |
| 000800 - 00FFFF | 1110xxxx 10xxxxxx 10xxxxxx |
| 010000 - 10FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
UTF-8的特点是对不同范围的字符使用不同长度的编码。对于0x00-0x7F之间的字符,UTF-8编码与ASCII编码完全相同。UTF-8编码的最大长度是4个字节。从上表可以看出,4字节模板有21个x,即可以容纳21位二进制数字。Unicode的最大码位0x10FFFF也只有21位。
例1:“汉”字的Unicode编码是0x6C49.0x6C49在0x0800-0xFFFF之间,使用3字节模板了:1110xxxx 10xxxxxx 10xxxxxx.将0x6C49写成二进制是:0110 1100 0100 1001, 用这个比特流依次代替模板中的x,得到:11100110 10110001 10001001,即E6 B1 89.
例2:Unicode编码0x20C30在0x010000-0x10FFFF之间,使用用4字节模板了:11110xxx 10xxxxxx 10xxxxxx 10xxxxxx.将0x20C30写成21位二进制数字(不足21位就在前面补0):0 0010 0000 1100 0011 0000,用这个比特流依次代替模板中的x,得到:11110000 10100000 10110000 10110000,即F0 A0 B0 B0.
3)ASCII
ASCII(American Standard Code for Information Interchange,美国信息互换标准代码)是ANSI(American National Standards Institute)美国国家标准学会的规范标准,世界上所有的计算机都用同样的ASCII方案来保存英文文字。因为ASCII没有可以利用的字节状态来表示汉字,
中国人在ASCII的基础上,通过组合的方式,组合除了大约7000多个简体汉字,把这种方案叫GB2312, GB2312是对ASCII 的中文扩展。
4)GB2312
中文文字数目大,而且还分为简体中文和繁体中文两种不同书写规则的文字,而计算机最初是按英语单字节字符设计的,因此,对中文字符进行编码,是中文信息交流的技术基础。
我国国家标准总局1980年发布《信息交换用汉字编码字符集》,标准号是GB 2312—1980,它是计算机可以识别的编码,适用于汉字处理、汉字通信等系统之间的信息交换。基本集共收入汉字6763个和非汉字图形字符682个。
GB2312的出现,基本满足了汉字的计算机处理需要,它所收录的汉字已经覆盖中国大陆99.75%的使用频率。
1995年国家标准总局又颁布了《汉字编码扩展规范》(GBK)。GBK与GB 2312—1980国家标准所对应的内码标准兼容。
对于人名、古汉语等方面出现的罕用字,GB2312不能处理,这导致了后来GBK及GB18030汉字字符集的出现。
注意:
UTF8 只是 UNICODE内码在存储/传输时的状态。 而从GB2312编码转换到UNICODE编码需要查表。 UTF8 和 UNICODE 的关系 与 GB2312 和 UNICODE的关系有本质的不同。 UTF8 和 UNICODE 是一个人的两个面孔, GB2312 和 UNICODE 是两个人。 所以,要实现UTF8编码到GB2312编码的转换必须先把 UTF8编码还原为UNICODE编码,再通过查表的方式,把UNICODE编码转化为GB2312编码。
5)Latin1
Latin1是ISO-8859-1的别名,有些环境下写作Latin1,是单字节编码,向下兼容ASCII.
3.Linux字符集
提到linux字符集就不得不说locale.locale 是国际化与本土化过程中的一个非常重要的概念,对于中文用户来说,通常会涉及到的国际化或者本土化,大致包含两个方面:看中文,写中文, locale的设定与看中文关系不大,但是与写中文有很密切的关系。
locale这个单词中文翻译成地区或者地域,其实这个单词包含的意义要宽泛很多。Locale是根据计算机用户所使用的语言,所在国家或者地区,以及当地的文化传统所定义的一个软件运行时的语言环境。这个用户环境可以按照所涉及到的文化传统的各个方面分成几个大类,通常包括用户所使用的语言符号及其分类(LC_CTYPE),数字 (LC_NUMERIC),比较和排序习惯(LC_COLLATE),时间显示格式(LC_TIME),货币单位(LC_MONETARY),信息主要是提示信息,错误信息, 状态信息, 标题, 标签, 按钮和菜单等(LC_MESSAGES),姓名书写方式(LC_NAME),地址书写方式(LC_ADDRESS),电话号码书写方式 (LC_TELEPHONE),度量衡表达方式(LC_MEASUREMENT),默认纸张尺寸大小(LC_PAPER)和locale对自身包含信息的概述(LC_IDENTIFICATION)。例如:
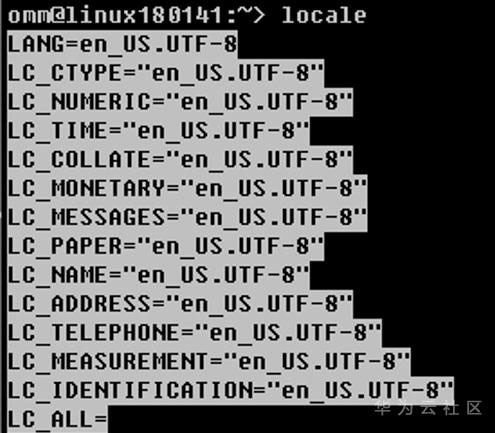
上面均说明LC_CTYPE(语言符号及其分类)表示这个系统的系统现在使用的字符集是en_US.UTF-8,LC_NUMERIC(数字)等其它与语言相关的变量。通常如果其它的语言变量都未设定,仅设定LANG这个变量就可以缺省代替所有其它变量了。
Locale实际就是某一个地域内的人们的语言习惯和文化传统和生活习惯。一个地区的locale就是根据这几大类的习惯定义的,这些locale定义文件放在/usr/share/i18n/locales目录下面:
4.GaussDB For DWS 字符集
GaussDB for dws 默认使用sql_ascii作为默认字符集,ASCII存储的是单字节流,并且没有能力判断多字节字符的有效性, 所以会一股脑存储进去,换句话说你可能在SQL_ASCII中存储了utf8编码的字符, 也存储了gbk编码的字符, 还存储了其他编码的字符。 那么要将sql_ascii转换成UTF8就不是一件易事了, 会遇到多种字符的转换工作。
如果数据库的编码为SQL_ASCII(可以通过“show server_encoding”命令查看当前数据库存储编码),则在创建数据库对象时,如果对象名中含有多字节字符(例如中文),超过数据库对象名长度限制(63字节)的时候,数据库将会将最后一个字节(而不是字符)截断,可能造成出现半个字符的情况。
针对这种情况,请遵循以下条件:
保证数据对象的名称不超过限定长度。
使用例如utf-8编码集做为数据库的默认存储编码集(server_encoding)。
不要使用多字节字符做为对象名。
结合以上情况,在GaussDB for dws初始化创建数据库时需要根据业务场景设置字符集。GaussDB for dws支持的字符集(编码格式): GBK、UTF-8和Latin1编码格式,多个数据库可以设置为不同的字符集。
| 字符集 | 规划原则 | 设置方法 |
| GBK | 如果数据库只需要支持中文,数据量很大,性能要求也很高,那就应该选择双字节定长编码的中文字符集。对GaussDB for dws来说,目前只能选择GBK 。 | 在安装数据库时指定初始化参数-E。
通过SQL语句创建数据库时指定ENCODING参数。 |
| UTF-8 | 如果应用程序要处理各种各样的文字,或者将处理结果发布到使用不同语言的国家或地区,就应该选择Unicode字符集。对GaussDB for dws来说,目前只能选择UTF-8 。 | |
| Latin1 | 如果数据库只需要支持ASCII收录的字符、西欧语言、希腊语、泰语、阿拉伯语、希伯来语对应的文字符号,则可以选择Latin1。 |
在使用GaussDB for dws过程中,服务端和客户端都可以设置字符集。由于服务端与客户端可以设置为不同的字符集,所以两者字符集中单个字符的长度也会不同,所以产生的最终结果可能会与预期不一致。如果服务端与客户端设置为不同的字符集,则客户端输入的字符串会以服务端字符集的格式进行处理,很有可能产生与预期不一致的结果。
| 操作过程 | 服务端和客户端编码一致 | 服务端和客户端编码不一致 |
| 存入和取出过程中没有对字符串进行操作 | 输出预期结果 | 输出预期结果(输入与显示的客户端编码必须一致)。 |
| 存入取出过程对字符串有做一定的操作(如字符串函数操作) | 输出预期结果 | 根据对字符串具体操作可能产生非预期结果。 |
| 存入过程中对超长字符串有截断处理 | 输出预期结果 | 中字符编码长度是否一致,如果不一致可能会产生非预期的结果。 |
客户端及服务端字符集设置方法:
client_encoding: 客户端的字符编码类型, 根据前端业务的情况确定。尽量客户端编码和服务器端编码一致,提高效率。
参数类型:USERSET(普通用户参数,可被任何用户在任何时刻设置。)
取值范围:兼容PostgreSQL所有的字符编码类型。其中UTF8表示使用数据库的字符编码类型。
说明:
使用命令locale -a查看当前系统支持的区域和相应的编码格式,并可以选择进行设置。
默认情况下,gs_initdb会根据当前的系统环境初始化此参数,通过locale命令可以查看当前的配置环境。
参数建议保持默认值,不建议通过gs_guc工具或其他方式直接在postgresql.conf文件中设置client_encoding参数,即使设置也不会生效,以保证集群内部通信编码格式一致。
参数设置方法:
gs_guc reload -Z coordinator -Z datanode -N all -I all -c " client_encoding =utf8"
SET client_encoding TO utf8;
server_encoding
参数说明:报告当前数据库的服务端编码字符集。该参数属于INTERNAL类型参数,为固定参数,用户无法修改此参数,只能查看。
5.常见问题
乱码及报错
简单的说乱码的出现是因为:编码和解码时用了不同或者不兼容的字符集。在计算机科学中,一个用UTF-8编码后的字符,用GBK去解码。由于两个字符集的字库表不一样,同一个汉字在两个字符表的位置也不同,最终就会出现乱码。
因client_encoding与server_encoding设置不一致,导致报错或者乱码。
示例:
测试数据:
创建数据库,字符集为gbk,导入数据
CREATE DATABASE gbkdb ENCODING 'GBK' template = template0;
创建测试表
create table t_gbk(id int,name varchar);
导入数据
copy t_gbk from '/home/omm/encode/test.csv' with(format 'csv',encoding 'gbk');
查询表数据报错
select * from t_gbk;
问题定位:
查看server_encoding及client_encoding
因为数据是按照GBK存储的,使用utf-8查看,在转码时发生错误。
解决方案:
设置client_encoding=’GBK’
查询不再报错,但是显示仍是乱码
设置crt工具字符集
查询数据:问题解决。
评论(0)