简明、现代而优雅 特别篇:扫盲及入门建议
简而言之,想要破解程序,就要先认识程序。想要认识程序,就要先明白世界上所有的程序都是怎么来的。本文旨在让你弄明白世界上所有的程序各是怎么来的,无一例外。清楚了这些,我们就可以根据程序的来源逐一击破。
第一节课已经发出来了,但是感觉还是不如一些直接教过时方法论的教程火。不过依然收获了很多关注,感谢一直关心这些最新技术的朋友。也衷心希望可以听到大家的建议,让我能够对大家有更大的帮助。
由于我是计算机科学与技术专业科班出身,有很多本科一年级就耳熟能详的常识,我想还是需要向大家普及一下。否则小白可能还是会觉得教程艰深,而网上盛传的各种说法也不是都自洽,所以我决定先插一期扫盲帖,从我们学习逆向工程所要分析的目标:软件的历史开始讲起。
为了使计算机更易于使用(编程),自电子计算机发明以来,无数人在它的基础上添加了一层又一层抽象和包装,每一层抽象和包装都可以称作一个平台,同一层的不同方法的抽象和包装又可以称为同一层的不同平台。这些平台大致可以分为操作系统、编程语言、软件框架三个大类,而且他们之间的界限存在,却不一定完全清晰。这些抽象和包装百花齐放,百家争鸣了六十多年,最终形成了我们现在看到的使用电子计算机构建的复杂世界。虽然这些抽象和包装是为了让人们不去在意机器的逻辑,而是使用人类的思维方式来告诉机器自己的意图,但是最终生成的程序是要由机器来执行的。当我们拿到一份由机器执行的程序时,我们必须把这一整个过程还原出来,从机器要做什么反推出人在最高层次的抽象和包装上想要让机器做什么,这就是逆向工程的本质。因此,想要学习逆向工程,最符合实践的方法是理解那些抽象和包装是如何得出的,并且在底层的基础上建构出整个逻辑链,从而找到原设计者本身的意图,并且在此之上添加自己的意图(破解)。
早期的电子计算机
虽然这一节的名称叫做“早期的电子计算机”,但即使是今年刚推出的各种架构的CPU和GPU,硬件上也依然和早期的计算机类似(冯·诺伊曼结构),当然也有些产品会有所不同(哈佛结构)。如果你喜欢研究裸机编程,依然可以在这些最新的硬件上进行裸机编程。现在流行将现代的裸机硬件称为“裸金属”(Bare Metal),可以搜索这个关键词来获取这个领域的最新信息。另外,一些低端计算机、MCU(单片机)等,也依然使用这种编程方式。
在早期的电子计算机上,我们直接在计算机的存储器上编写程序,并且计算机从存储器的固定位置开始执行代码,除代码外的存储空间,看情况,有的存储器可以用来随意存储数据,有的存储器则不能。直接在存储器上编写程序的时候,需要对照计算机的操作手册,查询对应指令的代码,并将代码和数据写在存储器上。这个时候,没有任何编程语言,也没有操作系统,更没有软件框架。你所拥有的一切就是一本说明书,以及你可以根据这本说明书来编写机器指令操作这台电子计算机。时至今日,英特尔、AMD等CPU设计企业依然在为他们的产品编写这种说明书,但这些说明书的受众变小了,只有微软和写其他操作系统以及开发BSP(板级支持包)的人才会去参考,但在操作系统和BSP出现之前,这是一名计算机操作员手头必备的资料。
为了便于理解直接在计算机的存储器上编写程序这件事情,大家可以看看非常早期的计算机。那时计算机的存储器是穿孔纸带,人们可以直接在纸带上穿孔,穿好孔的纸带便被写入了程序。这一切到今天为止依然类似,只是存储器也变成了电子元件而已。
研究早期计算机的人是幸运的。我本科时期刚好参与了“珠峰计划”,我校在这个项目中对计算机硬件课程做了一次重新整理,把一般本科学习的“计算机组成原理”和“计算机系统结构”两门课程统一成了一门大课“计算机硬件系统设计原理”,由退休返聘老教授刘子良先生亲自操刀写书授课,我很荣幸成为了他的学生。听他讲课时,经常能够听到一些六七十年代的奇闻轶事。他使用过打孔纸带编写计算机程序,也亲眼见过大型机的内部结构。只有这样的人才能亲眼看见AX、BX寄存器,才能亲手摸到RSP、RBP.我们现在再去学习这些的时候,只能对着课本上的示意图和调试器、仿真器中的参数想象,在小小的芯片中居然存在这么一个东西,我们永远也不能看得见摸得着了。
操作系统的出现
在使用打孔纸带编写机器指令并把数据直接写在机器指令里的年代,没有人觉得电子计算机开一次机只运行一条纸带,运行完毕后从计算机上连接寄存器的亮起的灯上读出数据,再把计算机停机复位,需要运行下一段程序的时候再开机有什么不对的地方。但是很快,存储器技术就出现了革新。磁鼓存储器让人们可以不再使用打孔纸带来承载数据,而是把数据变成了磁鼓上的磁场。电子化的存储器很快让寻找和安装纸带的过程变成了电信号,由一些控制电路来控制。
人们终于感觉每次开机只运行一条程序有点效率低下了(那是因为电子存储器解放了人类寻找纸带的双手)。于是有的计算机使用者便编写了一些让计算机在一段时间内保持运行,并且根据某些按钮输入可以从存储器的不同位置加载不同的程序来运行的程序,这便是最初的操作系统。是的,操作系统就是帮助人操作计算机的系统,从这个时候起,计算机装载程序变得更方便了,而且程序和数据也可以尽量分类好了。同时,数据存储技术百花齐放,有些存储器价格比较低,但性能也比较拉跨,有些存储器价格比较高,但性能也非常顶。所以,计算机系统慢慢发展出了内存储器和外存储器的设定,内存储器用来给程序打草稿,外存储器用来存放初始的某些数据和最终的结果。
其实这些史前时代的故事众说纷纭,本文的说法也不一定就完全符合史实。因为在历史的开端是没有人修史的,当人们开始意识到操作系统的重要价值时,操作系统就已经基本有一个雏形了。那就是用来装载和切换程序的那个“管理程序的程序”。当一些计算机制造商开始制造出性能非常强悍的计算机时,他们将自己的计算机高价卖给一些机构,并不是所有人都买得起计算机,所以这些机构租用计算机的生意就非常火热。为了方便管理计算机的租用,就有了更加高级的操作系统。这种操作系统可以让不同用户提交的任务以为自己独占了计算机,而实际上却是来回切换执行的,并且能够计时,然后按照用户的身份来记账。
这其实与现代的操作系统已经别无二致了,有随时装载程序的功能,还有进程和用户管理的功能。事实上,这种操作系统有一个大名鼎鼎的后代,就是Unix.Unix起初是直接用机器指令编写的,后来Unix的主要作者Dennis MacAlistair Ritchie觉得需要开发一门高级语言来改善Unix上的编程体验,于是就发明了C语言(写出了第一个C语言编译器),并把C语言编译器和Unix系统都使用C语言本身重写了一遍。
高级语言的产生
上文提到了C语言,不如我们直接开始讨论高级语言。C语言其实并不是最早的高级语言,高级语言的出现主要是为了提升计算机上的编程体验。你不再需要记住那些烦人的指令,现在你的心里只需要有逻辑控制结构,就可以轻松写出很多程序。高级语言的出现大大减低了编程时逻辑思考的难度,使得计算机程序的逻辑复杂度提升了不少(这个道理很简单,当你不再注重那些细节的时候,你就可以思考更多大体上的事情)。
所以高级语言的核心技术就是前文中提到的编译器。编译器做的事情就是把高级语言翻译成机器指令,这其中就涉及巨量的细节被编译器自动处理,而且编译器有不低的自由度。以前在使用机器指令编程时,你能控制机器如何执行代码的唯一方式就是跳转类指令。高级语言定义了一些新的逻辑,比如判断和循环,这些基本结构都是机器不能理解的,但是编译器可以把他们转换成一些包含跳转和判断的指令,让机器可以按照这些逻辑意图做出动作。从此开始,人和机器不再同步思考,人编写程序,编译器将人类逻辑翻译给机器,机器按照机器的方式执行。
高级语言是编译器的语言,使用高级语言编写程序,就相当于人指挥编译器制作和装配一个程序。除了可以直接一一对应机器指令的汇编语言外,其余所有的语言都叫做高级语言,所以现在很少有人再提高级语言的概念,因为高级语言内部也有很多分化,与操作系统和软件框架也息息相关。几乎都是某一个平台上为了提升本平台的编程体验而发明的东西,或者一些团体为了在多个平台上提供一致的体验发明的东西。
既然高级语言编写的程序最终要由编译器生成实际运行的程序,那么这种实际运行的程序或许可以反编译成高级语言的代码。如果是编译器直出,没有经过任何处理的可执行文件,的确可以被反编译成源代码——只需要把编译器中处理的那些语句和指令之间的对应关系反过来就好了。最初的高级语言和编译器确实是这样的。但是现代的编译器都会在编译完源代码之后,甚至在编译的过程中,对于生成的机器指令进行优化,这是一种自动的骚操作,大多数时候可以提升程序的性能,或者至少统一程序的性能。这样就有一个副作用,生成的机器指令无法被准确判断出来自什么样的源代码,也就需要具体问题具体分析了。这也是逆向工程中的第一步难点。
后续的发展
其实说了这么多,我主要是想表达,其实在机器指令之上,任何后续的发展都是为了让人“更加舒适地编程”,并且有很多人提出了很多解决问题的方法。并且任何一项技术,通常都不是一个单独的技术点,而是给人提供编程体验的一整套方案。只是大家通常对于这种方案的认知都仅仅在一个点上。例如操作系统,当今所有操作系统都选择使用C语言接口作为系统官方最基础的编程体验,但这并不妨碍很多人使用其他的方案在操作系统上编程。使用其他的方案在操作系统上编程,只要方案提供者允许,同样可以使用操作系统的各项功能,同时也包括方案提供者的各种扩展。所以,作为一个破解者,也许我们需要破解的程序是千变万化的,但如果我们能够根据方案的发展程度从合适的层面切入,我们就可以获得事半功倍的效果。
什么叫做根据方案的发展程度从合适的层面切入呢?首先还是要继续普及一下编程方案的发展。自从高级语言发明出来之后,高级语言编程方案的提供者就代替他的用户成为了计算机制造商的客户。高级语言方案的提供者(最初有些人甚至是志愿的),会想方设法把自己的高级语言移植到各种计算机上,这些计算机都不是一个地方产的,所以指令也不是同一套,这就意味着他要编写一个将自己的高级语言编译到这套指令(指令集)上的编译器。有些计算机的指令集功能多,有些计算机的指令集功能少,每一个都需要单独研究,才能写出一款用来编译高级语言的编译器。
那这就有点恼火了,更要命的是,其实计算机干的无非也就是计算的活,所以指令集虽然大家都不一样但是其实也差不多。所以就有人动起了脑筋,如果我把这些指令集里面相同或者相似的东西,都抽象出来,然后研究这个抽象层到具体指令集的转译方法,同时把我的高级语言编译到这个中间的指令集来,岂不是就能省好多事了?
是的,就是这种一遍一遍的抽象,构成了今天的计算机世界。
一般喜欢省事和弯道超车的人都喜欢踩别人上位,这种搞“中间编译器”的语言也不例外。C语言几乎已经成为了全世界高级语言的霸主,你如果想发明一门语言弯道超车C语言,你会怎么做呢?首先,用C语言写前面提到的转译器,然后,由于C语言支持的平台最多,你的转译器可以随随便便编译到任何平台上。然后编写一个从你的高级语言源代码到中间指令集的编译器,这样,你编译出来的程序就可以通过你的转译器跑在任何平台上,而且只需要编译一次!编译一次就可以拿着文件在各种平台用相应的转译器运行,比C语言不知道高到哪里去了。
这就是Java,我希望易语言的后人们学着点,真的。
后来,这种中间指令集被各路计科大神整理规范,最后形成了一种“语言虚拟机”的概念。就是说这种中间指令集是一种假想的机器的指令集,你的编译器是往这种假想的机器上编译的,而这个假想的机器被你的转译器实现了,只不过你的转译器底层是用其他的计算机实现的这个功能。这种思想后来被LLVM吸收,用来优化C语言的编译过程。
好家伙,套娃终于套起来了。
再后来,由于Unix系统本身的命令行就可以执行一些逻辑,比如判断和循环,但是并不太优雅,所以有人实现了一些其他的交互式命令解析器,来执行一些需要复杂功能的命令。命令太多了,人们就把他保存在文件里,并且解析器可以读取这种文件,来执行文件里面的一套命令,这也算是一种编程了,这被称为脚本编程,Windows的BAT批处理也算是这种编程。
脚本编程用的语言自然也就被称为脚本语言,脚本语言现在也算作是编程语言。因为我们同样可以为脚本语言开发编译器,比如BASIC和Python都是脚本语言出身,但微软为BASIC开发了编译器,并且开发了开发BASIC图形界面程序的工具Visual Basic,而Python现在也是编译到Python虚拟机来执行了。
编程语言的分类
作为学破解的各位朋友,对编程语言的分类可能需要一个和学界不一样的理解。学界从来没有把编程语言分成过三类,要么是“编译型语言/解释型语言”,要么是“动态语言/静态语言”。这些都不适合用来分类以逆向工程观点来看的程序语言。所以我在此提出,按照上文逻辑,将编程语言,或者说可以在计算机上运行的程序分为以下三类:
- 原生语言:编译到平台原生机器指令的语言
- 虚拟机/框架语言:编译到虚拟机指令的语言
- 脚本语言:不编译,直接解释执行的语言
在这个分类下,典型的语言有:
原生语言
汇编、C/C++、Pascal、Go、Rust、VB
虚拟机/框架语言
Java、C#、F#、VB.net,以及一大堆基于JVM的语言,如Kotlin、Scala
脚本语言
Shell脚本、Windows批处理脚本、Python、Ruby、VBScript、JavaScript
当然,同一款语言可能同时存在多种运行方式,但这三种运行方式分别对应三种破解与防破解策略。你的逆向层面越接近源代码编写的层面,你就越容易获得源代码。举个例子:如果你正在使用一个Python脚本,你想要修改他的逻辑,你会傻到打开调试器x64dbg,然后附加到Python解释器进程,然后去修改Python解释器进程的内存吗?直接修改你正在运行的Python脚本就是了。
方法论环节
所以,今天的方法论终于来了,那就是,确定好你的目标程序属于哪一个层面的语言,并且使用对应层面的逆向工具。如果你确定你要破解原生程序,那就请使用IDA和x64dbg,以及CheatEngine.如果你要破解虚拟机程序,比如C#的程序,那就请用dnspy直接从。net虚拟机指令反编译源代码,并且改完以后再编译回去。如果你想破解脚本程序,就请直接修改你所看到的代码,那就是源代码!
想要知道一个exe程序属于原生层面还是虚拟机层面,或者加没加壳,不要使用其他工具,请认准Exe Info PE!这才是现代的万能查壳工具。当你看到。net关键词时,就代表你要破解的exe是个。net虚拟机层面的程序,使用dnspy,而不是IDA!
简明、现代而优雅 前言
一转眼的时间 Windows 10 已经发布6年了,距离 Windows XP 停止一切支持服务也已经过去了七年。距离英特尔发布第一款64位处理器已经过去了15年,AMD 发明 x86-64 也已经是18年前的事了。十二年前,Windows 7 正式发布,大多数预装 Windows 7 的电脑都采用了英特尔最新的64位处理器,标志着个人电脑正式进入64位时代。与此同时,iPhone引领了世界智能手机市场最大的变革,掀起了移动互联网的风潮,推广了Emoji和同系统多国语言文字共存,从而推进了Unicode的普及。可以说,站在当今的视角下,如果一个程序不是Unicode内码的64位程序,那么他就不是一个现代的程序。
很遗憾的是,当前中文互联网上的破解教程,依然停留在21世纪初 Windows XP 刚刚发布时的水平,只能处理过时的程序。作为一个新时代的新手,不应该为历史所困,直接丢掉历史包袱,学习最新的技术,有助于快速提高自身水平,跟上业界发展。
我也是一个新手,当我看到各种教程教我创建XP虚拟机来运行各种老古董破解工具,不能破解64位软件,还需要装插件或者用一些奇怪的方法才能进行中文搜索的时候,我的内心实在是悲痛。好在我英语还过关,在混了一些国外论坛的基础上,我学到了一些新时代逆向工程的皮毛,借此整理记录下来,希望能对各位有所裨益。
基础理论
当你想学习逆向开发的时候,我觉得最重要的一点是你要有一些正向开发的基础知识,并且最重要的是了解一些在正向开发的过程中对逆向分析有用的原理,这样就能在学习逆向分析的过程中时刻思路清晰,而不是拘泥于一些知其然而不知其所以然的方法论。下面我将介绍一些与此有关的基础理论。
CPU与内存
作为一个新手,我们还是需要先了解一下计算机的基本结构。CPU负责运行指令并处理数据,而内存负责存储指令和数据。计算机的核心部件就是这两个东西。一般来讲,CPU先从内存中读取一批指令,然后执行,执行的过程中就会读写内存中的数据。所以CPU需要能够记住读取的一批指令,并且能够存储需要向内存读写的数据。所以CPU中有寄存器(用来存储数据)和指令缓存(用来存储指令)。CPU是一套很复杂的逻辑电路,作为这样复杂的一套逻辑电路,有一些基本的设计规定。比如CPU中的“一个”数据使用多少根线来表示,有几根线就可以代表几位二进制数,这也就是CPU的位数。无论是指令还是数据,在CPU的电路中其实都是数据。指令其实是一种规定,当碰到一个数的时候,如果他是从指令这边过来的,那么他就代表什么意思,CPU就要执行这个意思。例如 x86-64 CPU 碰到了B8 00 00 00 00,就知道要往eax寄存器中存入0x00000000.所以有人把数和意思之间做了一个转译,让人们可以不用记这些指令的具体数字,使用别名编程,这就是汇编语言。上例B8 00 00 00 00转换成汇编语言就是mov eax, 0x00000000.
操作系统平台
无论是正向开发还是逆向工程,都是建立在某一个操作系统或者平台之上的。作为一个新时代的新手,我们自然是使用最新版 Windows 操作系统。Windows 操作系统中的exe文件就是可以执行的程序文件,当我们双击exe文件时,Windows 就会创建一个进程,并读取exe文件的各个部分并且把这些部分装进进程内存的合适位置,然后从程序的入口点开始执行。程序执行时不可避免地会用到一些操作系统提供的功能,例如从控制台中读取和输出内容,这些功能微软官方都封装成了C语言的函数库,当你使用C语言或C++时可以很方便地调用,但使用其他语言时就必须使用第三方或者语言官方提供的调用方式了,如果没有提供,你需要学习 Windows 的 ABI(应用程序二进制接口),并且自己实现调用系统调用。这是一个至少不太适合新手的过程,并且没有任何第三方的实现比微软官方的稳定且优雅。所以如果想在 Windows 上优雅地编程,尤其是想要快速上手,我们应该使用微软官方提供的最新工具,也就是最新版 Visual Studio,并且使用C语言或C++来编写程序。
我的英语不好,我害怕
最新版的 Visual Studio 已经是完全汉化的状态,此外,Community版本(社区版)够用,而且是完全免费的。使用Unicode内码编写程序时,C/C++语言除了关键字有那么几个if、while、for、switch、case、void、int、float等,以及非中国人编写的函数库的功能是英文之外,其余任何位置都可以使用中文。C++标准委员会对于C++的标准库有全面的中文文档,可以对照参考,名称使用英文仅仅是为了“起个名”,名字总要有,而且用英文起对于全球人民来说是最方便的。与此同时,微软对于自己的Visual Studio也有全面的中文帮助文档。可以说,在现代学习C++语言,不存在任何语言障碍。另外,如果你在看过如此大量的全中文资料后依然感觉打英文字母就是不舒服,或许可能“伤害到了你的民族自尊心”的话,结合上一条,学会编写和分析现代化、优雅且稳定的程序应该比这一点点的不舒服重要太多了。
停止编写过时、混乱且不稳定的程序
是的,我几乎要点名易语言了,不支持64位,也不支持Unicode,并且编译出来的结果混乱不堪,既不是现代化的编程方案,也不足够优雅。最重要的是,不利于新时代正向和逆向开发的学习,请停止走弯路,拒绝过时和不够优雅的东西。
从下篇笔记开始,我将带领大家编写一个现代化的密码验证程序,并亲手破解它。
简明、现代而优雅 第一课
需要提前准备安装的工具环境
- Microsoft Visual Studio 2019 社区版(完全免费) 官网下载
- 安装时记得选择 C++桌面开发 工作负载
- IDA Pro 7.5 绿色版
正向开发:开始设计密码判断程序
即使你是一个连C++也没有接触过的新手,也不要害怕,下面我会演示如何用 Visual Studio 默认创建的 Hello World 代码修改出一个判断密码的小程序。
在 Visual Studio 中创建工程
打开 Visual Studio
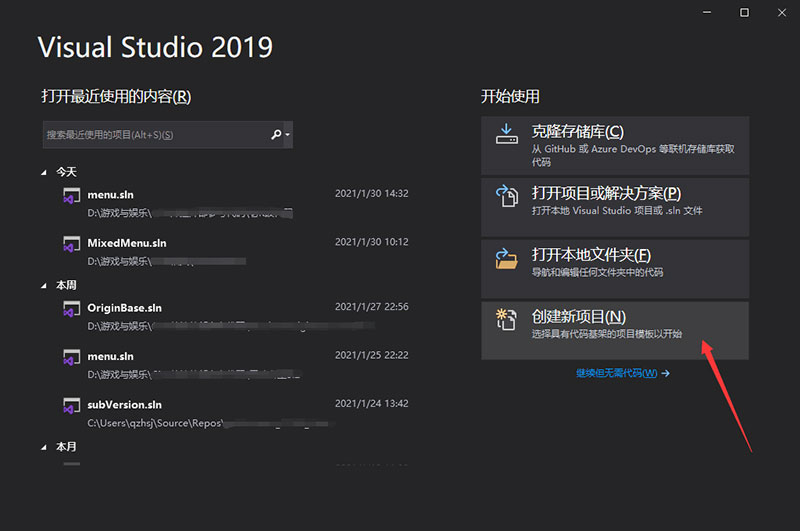
选择 创建新项目

语言选择 C++ ,平台选择 Windows 。
在列表中找到 控制台应用 ,并点击下一步。
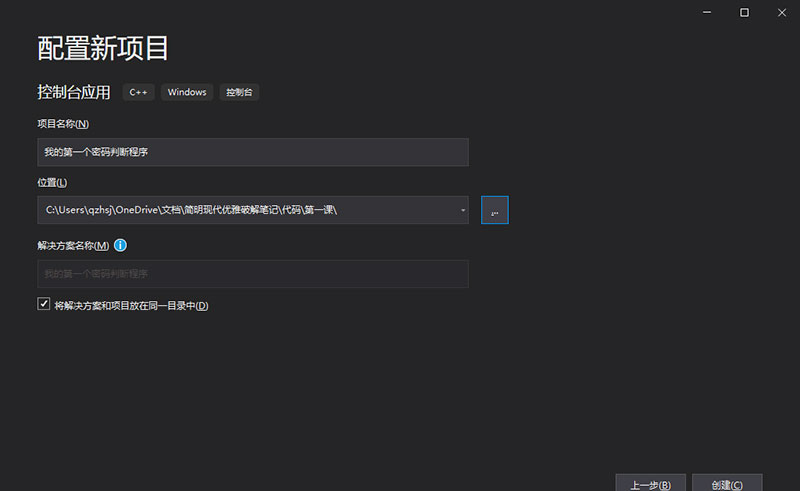
把项目位置改成你希望用来盛放你的作业的位置,并且给项目起个名字,比如 我的第一个密码判断程序 。
勾选 将解决方案和项目放在同一目录中 ,本例我们不需要复杂的解决方案与项目管理功能,勾选这一项可以减少文件夹层级,看起来顺眼一些。
点击 创建 。
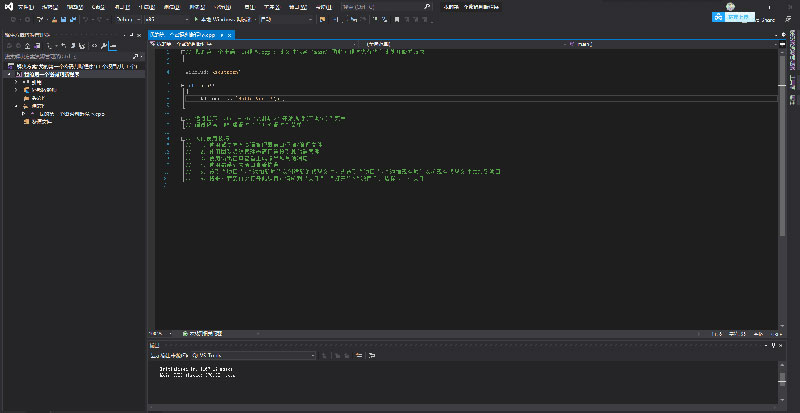
我们可以看到,Visual Studio 自动为我们配置好了工程,并生成了一个源代码文件,文件的内容是一个 Hello World 程序。
修改 Visual Studio 生成的初始程序代码
在上方的 Debug x86中把 x86 换成 x64 ,并点击右侧带有绿色小三角的 本地Windows调试器 ,就可以看到 Hello World 程序的运行结果。
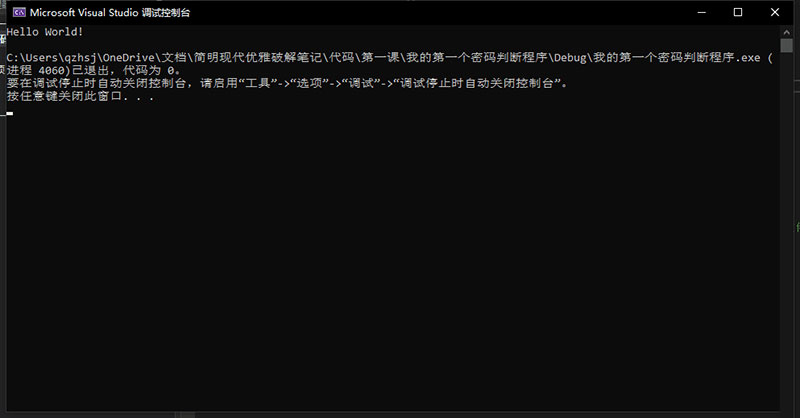
这就是这个程序代码的作用。将这个调试窗口关掉,我们继续查看程序代码本身。
如果你接触过一些基础的C++课程,或者至少知道如何编写Hello World,你会觉得很熟悉,这里面除去大括号之外的三行代码,第一行是引入 iostream 这个C++模块,第二行是定义了一个 main 函数,而第三行则是调用 iostream 模块中在 std 命名空间中定义的流对象 cout ,并通过 << 运算符来向 cout 中输出一个字符串 "Hello World!\n" 。
如果你没有接触过C++,完全不知道这三行代码是什么意思,也不要着急,上期所述的C++标准委员会的官方文档中对这些东西有详细解释,搜索关键字即可。
在C++标准委员会的文档中,我们可以搜索到 cout 和 cin 两个流的具体用法和示例代码,请点击链接:cin cout
根据以上查到的用法和示例代码,我们可以发现,如果我们想把用户输入读入一个变量,那么就可以 cin >> 这个变量; ,如果想要输出一个东西,我们就可以 cout << 这个东西; 。
在C++中,想使用的变量需要预先定义,而且需要声明该变量的数据类型。变量声明的语法是 变量类型 变量名; 。
于是,我们现在可以读入用户输入了,并且把它输出出来试一下。代码如下:
#include <iostream>
int main()
{
std::string 用户输入的内容;
std::cin >> 用户输入的内容;
std::cout << 用户输入的内容;
}
再次点击运行,你会发现你制作了一款复读机。
知道了如何输入和输出,我们现在只需判断一下用户的输入与真码是不是一致就可以了。另外,为了让程序独立运行时最后能够停住看结果,需要在最后加一个等待用户输入的命令。所以最后的代码变成了这样:
#include <iostream>
int main()
{
std::string 用户输入的内容;
std::string 真码 = "52Pojie-AngeloTheCat";
std::cin >> 用户输入的内容;
if (用户输入的内容 == 真码)
std::cout << "密码正确!\n";
else
std::cout << "密码错误!\n";
system("pause");
}
再次点击运行,至此,一个小小的密码验证程序就完成了。
这个密码验证程序似乎对中文的控制台用户输入有bug,也可能是我的系统开了强制Unicode内码的缘故,暂时没有解决。可能使用区分宽窄字符的C++标准库,并且系统窄字符默认编码是UTF-8时就会出现这个问题,如果想要bug少一些,处理输入的时候请尽量使用 conio.h 或Windows API.
逆向分析:使用IDA查看编译好的密码判断程序
IDA的安装与配置
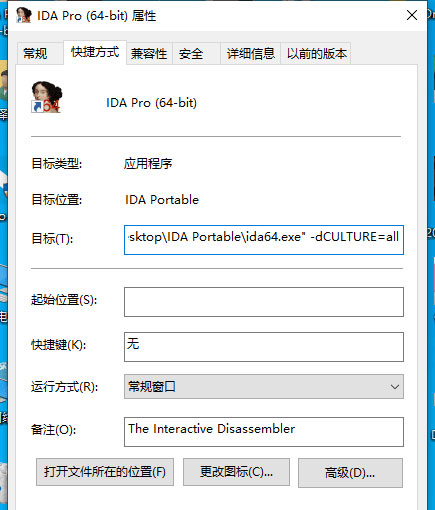
站长发的 IDA 7.5 是绿色版的,只需要绿化即可。
为了能够让IDA搜索中文字符串,需要在绿化后桌面上出现的 IDA 快捷方式中添加参数 -dCULTURE=all ,如图:
开始我们的第一次逆向分析
将我们编译好的程序拖入64位 IDA 的快捷方式,将会打开 IDA ,初次打开 IDA 时,会让你同意一个用户协议,同意即可。一般来讲,将程序拖入 IDA 后,将会弹出选择架构与 ABI 的界面,默认为 AMD64 架构和 Windows ABI ,这是正确的,所以这里点击OK.
之后 IDA 会弹窗告诉你,你要分析的这个exe文件存在一个调试符号表(PDB)文件,并询问你是否需要加载这个文件。这里我们选择“是”,看看得出来的结果是什么。

由于我们的程序非常小,IDA 很快就会加载完成。IDA 加载完成后会自动跳转到 main 函数的位置,这时显示的是 IDA 的流程框图,可以看到,好像已经出现了什么不得了的东西……
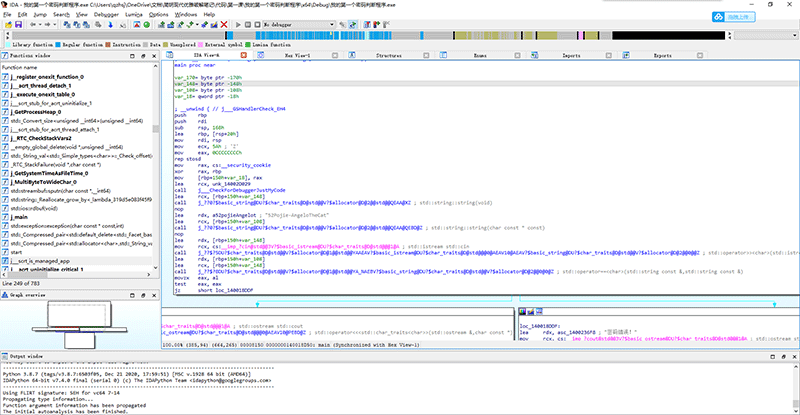
我们按下 F5 ,这是 IDA 的反编译快捷键,将会反编译当前选择的函数。

简直是不讲武德!我们刚才在main函数中所编写的逻辑,几乎一点不差地还原了出来。可以大致看到,if语句成立的条件是 v7==v8 ,而 v7 是调用了 cin 获取的用户输入,v8 则是密码的明文。
对于有C++基础的人,可以看到,从反编译后的第16行代码开始,和我们刚刚写的代码完全一致。先构造两个 string 对象 v7 和 v8 ,并且将v8初始化为真码的内容。再调用 cin 的 >> 运算符并且右操作数是 v7 这个 string 。然后调用 string 类的 == 运算符判断两个string,v7和v8是否相等,如果相等就调用 cout 对象的 << 运算符,输出密码正确的提示,否则就还是调用 cout 对象的 << 运算符,输出密码错误的提示。
而反编译的9-15行代码,则是 VC 的 Debug 版生成出来的程序自带的 Debug 环境初始化代码。
至此,由于我们写了一个实在太简单的程序,并且给IDA提供了符号表,所以我们轻而易举地就看到了这个程序的全部代码。我们现在来尝试修改这个程序的代码,将if的条件反向,密码正确时输出密码错误,密码错误时输出密码正确。
对第一个程序的修改(Hacking)
返回 IDA View 视图(框图),可以看到主函数的执行逻辑,左边是密码正确的逻辑,右边是密码错误的逻辑。区分走哪边是靠上面框中最后一条指令 jz 来实现的。
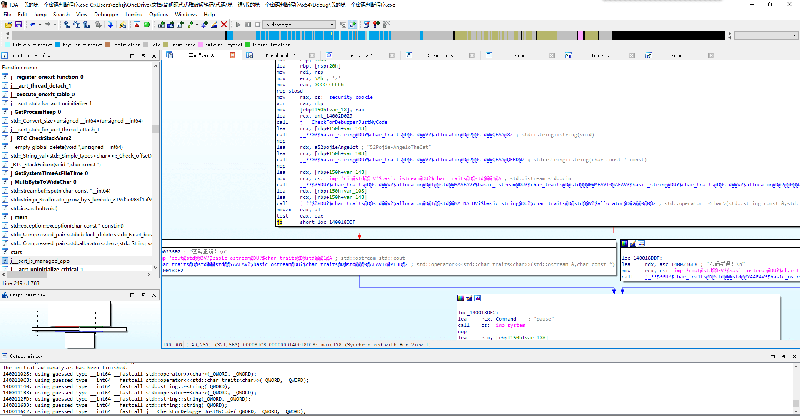
我们将光标定位在 jz 处,点击 Edit -> Patch program -> Assemble.
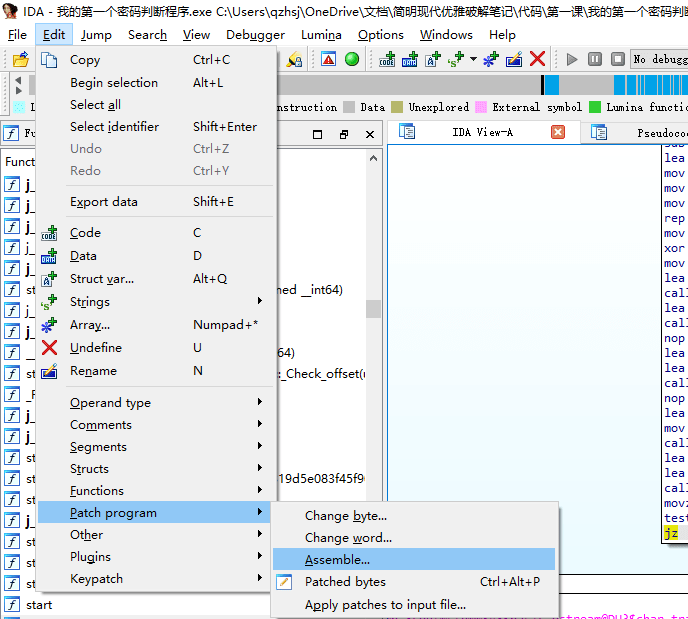
在弹出来的框中将 jz 改为 jnz.
点击 OK 后 IDA 会自动给你下一个地址处的汇编让你改,此处我们不需要继续再改了,应该停止修改,按 Cancel.
jz 是一条汇编指令,它一般和 test 一同出现。在上一条 test 中,如果用于比较的两个寄存器与起来的值是0(也就是说两个寄存器都是0),那么 jz 就会跳转。jz 的意思是 jump zero,为零时跳转,jnz 也是一条汇编指令,意思是不为零时就跳转。jz 和 jnz 也并不是一定要和 test 一同出现,他们判断为不为0的其实是CPU的状态寄存器。test 是一种会修改状态寄存器的指令。
再次按下 F5 ,看看生成的反编译代码 B 和之前的反编译代码 A 有什么区别。
点击 Edit -> Patch program -> Apply patches to input file.勾选 Create Backup 是个好习惯。
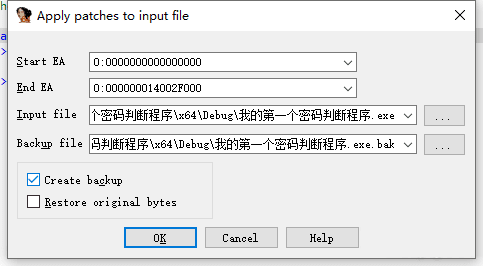
点击OK.运行一下你刚保存的程序,看看和你编写出来的原程序有什么区别。
恭喜你完成了人生中第一次破解自己写的程序!
在下一期内容里,我将带领大家对这个小程序做一些改进,至少不会让IDA一载入就在第一屏看见所有逻辑。
简明 现代而优雅 第二课
需要用到的工具
- Visual Studio 2019 官网下载
- IDA Pro 7.5 绿色版
- 第一课的一些知识
正向开发:另一个密码判断程序
思来想去,还是觉得每次用到任何东西的时候都把文档搬出来给大家看,一方面是我自己比较麻烦,思路总是断,另一方面,也使得文章内容重点不清,难以阅读。我的本意并不是想给大家上课,而是想以笔记的形式记录一些自己在破解实践过程中学到的东西。所以应该还是以思路连贯为主要目标,基础部分应该尽快略过,否则我永远无法真正开始写我的笔记。请大家见谅。如果你在阅读当中感到有任何不通顺或者不理解的地方,请一定要在楼下跟帖询问,或者如果你认为你问的问题与主题的相关性比较弱,也可以另开帖询问。
我依然会将需要用到的基础知识提前标示出来,方便大家查找其他资料来学习。本期正向开发中用到的知识有:
- conio.h
- C++的类和对象
- 状态机理论
需要实现的状态机
我们要判断用户输入的序列是否为“52pojie”,可构造以下状态机:(手头没有画图软件,手画了一个)
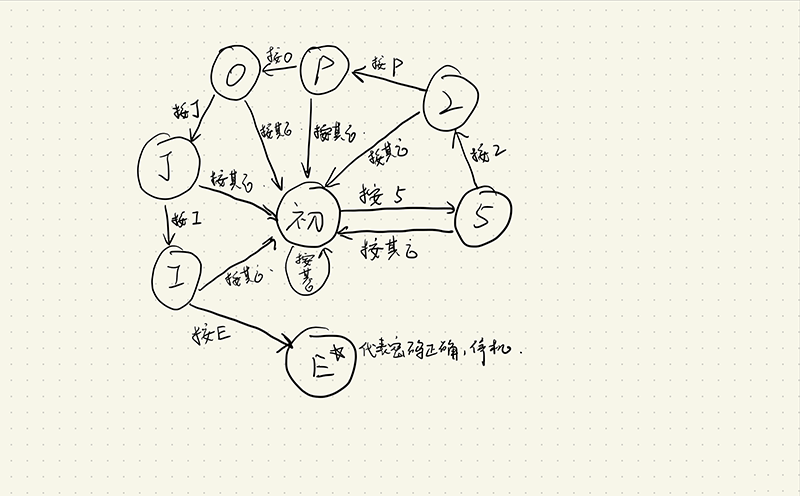
当这个状态机停机的时候,我们就知道,用户输入了正确的密码,否则这个状态机就会一直运行下去。
我们需要给状态机输入按键信息,来促进它的状态转移,同时我们还需要知道状态机是否停机,状态机停机后才能运行后续逻辑,否则就一直在密码状态机中运行。
所以状态机可以用C++类来实现:
class 密码状态机
{
private:
enum 状态
{
状态_初始状态,
状态_5,
状态_2,
状态_P,
状态_O,
状态_J,
状态_I,
状态_E_停机,
};
状态 当前状态;
public:
密码状态机()
{
当前状态 = 状态_初始状态;
}
~密码状态机(){}
void 状态转移(char 用户输入字符)
{
switch (当前状态)
{
case 状态_初始状态:
{
用户输入字符 == '5' ? 当前状态 = 状态_5 : 当前状态 = 状态_初始状态;
}
break;
case 状态_5:
{
用户输入字符 == '2' ? 当前状态 = 状态_2 : 当前状态 = 状态_初始状态;
}
break;
case 状态_2:
{
用户输入字符 == 'P' || 用户输入字符 == 'p' ? 当前状态 = 状态_P : 当前状态 = 状态_初始状态;
}
break;
case 状态_P:
{
用户输入字符 == 'O' || 用户输入字符 == 'o' ? 当前状态 = 状态_O : 当前状态 = 状态_初始状态;
}
break;
case 状态_O:
{
用户输入字符 == 'J' || 用户输入字符 == 'j' ? 当前状态 = 状态_J : 当前状态 = 状态_初始状态;
}
break;
case 状态_J:
{
用户输入字符 == 'I' || 用户输入字符 == 'i' ? 当前状态 = 状态_I : 当前状态 = 状态_初始状态;
}
break;
case 状态_I:
{
用户输入字符 == 'E' || 用户输入字符 == 'e' ? 当前状态 = 状态_E_停机 : 当前状态 = 状态_初始状态;
}
break;
}
}
bool 是否停机()
{
return 当前状态 == 状态_E_停机;
}
};
main函数
有了刚才构造的状态机,我们的main函数就好写了,只需要将用户的键盘输入喂给状态机做状态转移,并等待状态机停机(这代表密码输入正确),然后执行后续逻辑(打印“密码正确!”)。
所以我们最终写出来的main函数如下:
#include <iostream>
#include <conio.h>
int main()
{
密码状态机 密码状态机实例;
while (!密码状态机实例。是否停机())
{
密码状态机实例。状态转移(_getch());
}
std::cout << "密码正确!\n";
system("pause");
return 0;
}
运行一下,确实莫得问题。
逆向分析:第一次
这次我们依然使用IDA来进行逆向工程的工作。
试试IDA能把我们的程序怎么样
我们把Debug X64的程序直接拖到IDA里,加载PDB,IDA很快就完成了对程序的分析。
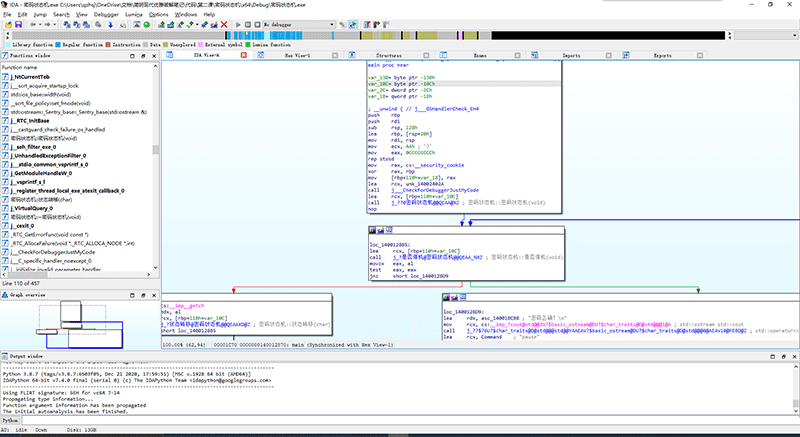
可以看到,左边甚至出现了我们定义好的密码状态机类的几个方法,main函数已经加载好了,我们直接按下F5.
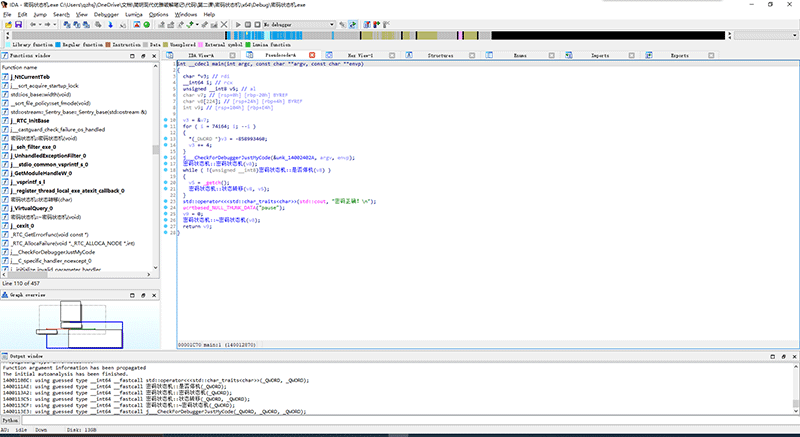
掀桌不玩了!每次我们自己写的程序一按F5就全看光了,还有什么好玩的!
出现这种情况的原因
因为我们使用的是Debug配置文件,Visual Studio默认会在这种配置文件中开启PDB(调试符号表)的生成,并且禁用一切优化,所以生成的程序代码异常规范,可以说是与源代码严格一一对应的。当然,这主要是为了Visual Studio自己调试起来方便,但也不可避免地为破解者开了一路绿灯。当IDA加载了PDB之后,便可以轻松知道源代码中你的各种变量、函数、对象、方法的命名,然后自动把这些符号映射到逆向分析出来的代码上。
这时依然要重申我一直在说的一句话,你的逆向工程开展的层次越接近源代码的层次,你获得源代码的可能性就越高。妄言原生程序无法看到源代码是非常不负责任的,事实上,如果原生程序与其源代码之间只隔了一个编译器,那么通过相应的反编译器,你自然可以获得程序的源代码。诚然,反编译器也是一种工具,是前人经验的集合,例如IDA中附带的C语言反编译器,就是Hex-Rays公司几十年逆向工程经验的结晶。在同一层面上,不同的技术有时可以互相代替,例如拿到一个原生程序,即使它不是用C语言编写的,也依然可以使用IDA内置的C语言反编译器将它反编译成C语言源代码。拿到一个Kotlin写的APP,你依然可以用JVM反编译工具把它反编译成Java源代码。此时,所谓的“源代码”也不一定就是软件作者编写出来的那一份源代码,但逻辑必然是相同的。这逻辑就是人类的逻辑,是程序语言描述的,被编译器翻译给机器执行的人类的逻辑。当你找到这一层逻辑的时候,你就是找到了你逆向目标的终极核心。
正向开发:使用Release重新编译
我们在Visual Studio中把Debug换成Release,并重新编译。编译完成后,需要特别指出,exe文件生成的目录和Debug版本不一样,请切换到Release版本的目录,再测试一下程序的运行情况。
逆向分析:第二次
将Release版本的exe拖入IDA,Release版本默认仍然会生成PDB文件,但我们这次在IDA中选择不加载,因为真正破解时你是拿不到软件原作者的PDB文件来开挂的。
初见Release版代码
加载完成后,IDA依然停在了main函数的位置,左边的函数框里也依然存在大量已经改好名字的函数,这是因为IDA有独立查找这些函数的能力。这种查找方法叫做“模式匹配”(pattern matching),也是我们将来要介绍的一个重点内容。顺便一提,模式匹配用的数据叫做“签名”(signature),在大多数国外论坛简称sig,这是一种非常重要的逆向工程经验资源,你可以看到很多人在交流这个。本站常说的易语言事件代码,也是一种签名。不是只有易语言才能用那种方法破解,只要你对于别人写程序时所用的框架和库有一定了解,你自己也可以积累这种资源。
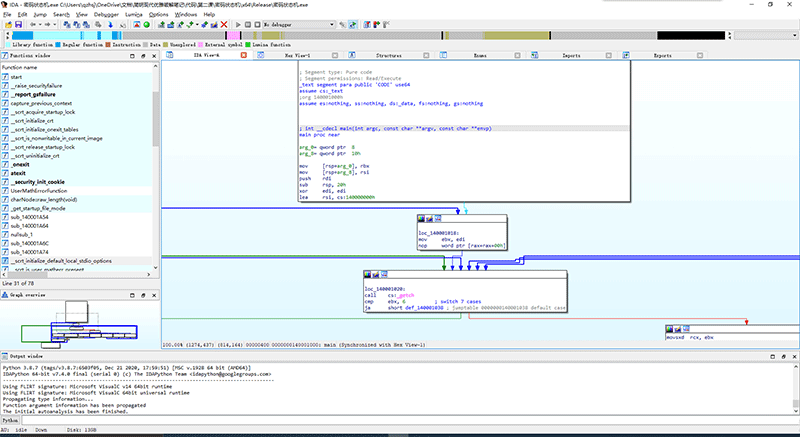
既然停在了main函数处,我们依然可以无脑F5,那么我们马上来试一下吧!
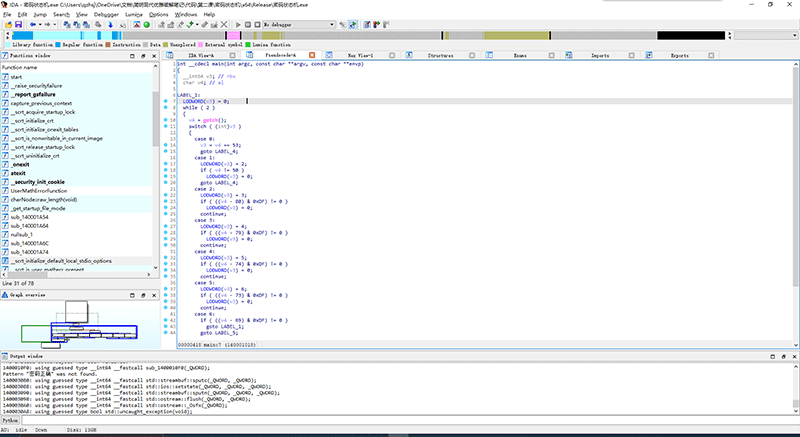
惊呆了,我的main函数完全不是这么写的呀!我的状态机类去哪了?怎么状态转移的switch case结构直接跑到main函数里来了?最后cout的时候为什么我看不懂?密码正确四个字去哪了?
“密码正确”去哪了
我们先来解决这个问题,在IDA上方的菜单栏选择Search -> Text.
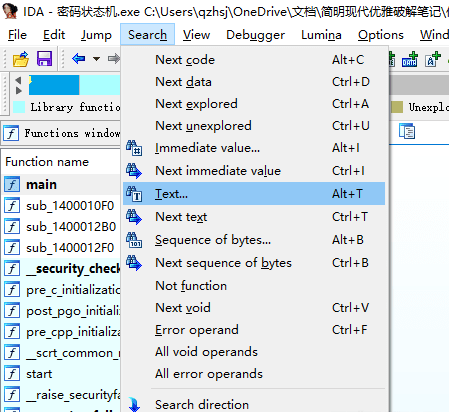
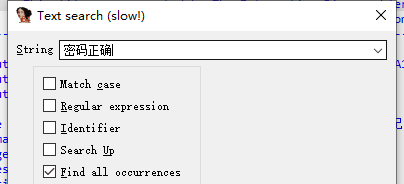
在弹出的窗口中输入“密码正确”,勾选Find all occurrences.
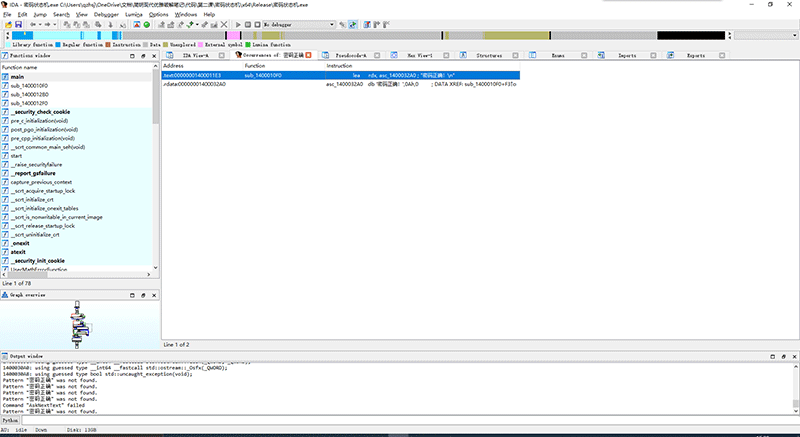
IDA很快就可以搜索出来结果。
如果无法搜索到中文,说明你的程序内码与IDA现在使用的系统内码不一致。我强烈建议大家开启Windows 10的“使用UTF-8提供全球语言支持”功能,并且在一开始就把所有程序代码存储为UTF-8格式,并在Visual Studio中将程序字符集设置为Unicode字符集。
想要开启“使用UTF-8提供全球语言支持”功能,需要点击开始->设置->时间和语言->区域->其他日期、时间和区域设置->更改日期、时间或数字格式->“管理”选项卡->更改系统区域设置->勾选“使用UTF-8提供全球语言支持”->确定,重启。需要注意的是,重启之后易语言等过时的软件会显示乱码,但其他正常的现代软件不会受到任何影响。你的开发和逆向体验都会变得比以前更加舒适,并且再也不用使用任何中文搜索插件即可搜索现代软件里的中文。
是什么东西输出了“密码正确”
搜索到“密码正确”后,我们直接双击找到的位置,可以直接跳转到出现“密码正确”的位置。两个都点击一遍后,我们可以发现,第一个是一段程序代码,第二个是程序数据,那段程序代码引用了这个程序数据。所以我们直接跳到代码部分。
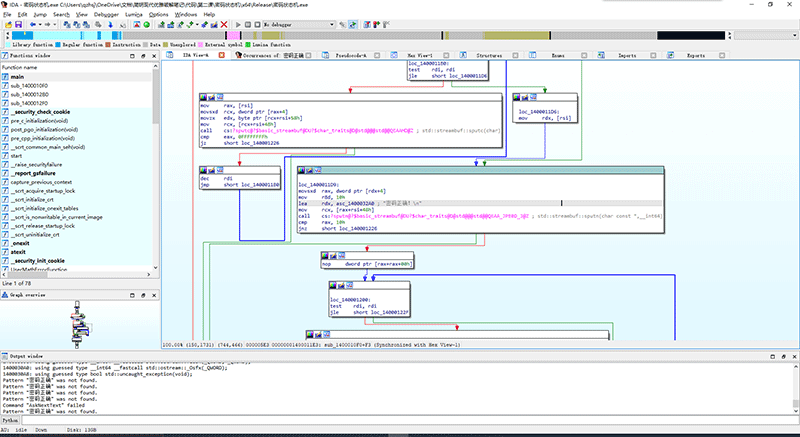
按下F5,直接看反编译的C代码。
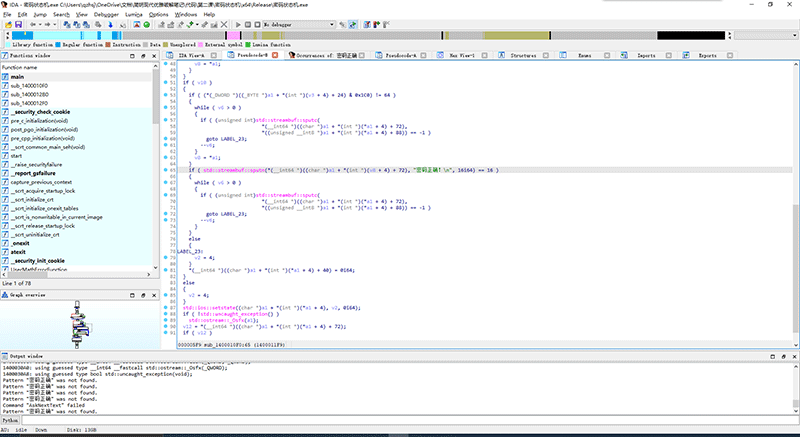
这就是具体处理输出“密码正确”的部分代码了。鼠标滚轮滚到最上方,我们看看这是哪个函数。
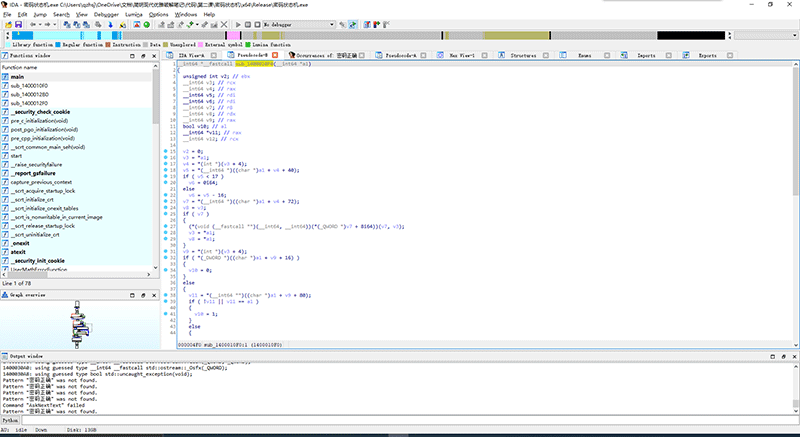
选中这个函数名并按下N键,即可打开重命名对话框。将这个函数重命名为“执行输出密码正确”。
可以看到,虽然反编译窗口这边没能正常显示中文,但左边函数窗口中出现了“执行输出密码正确”函数。
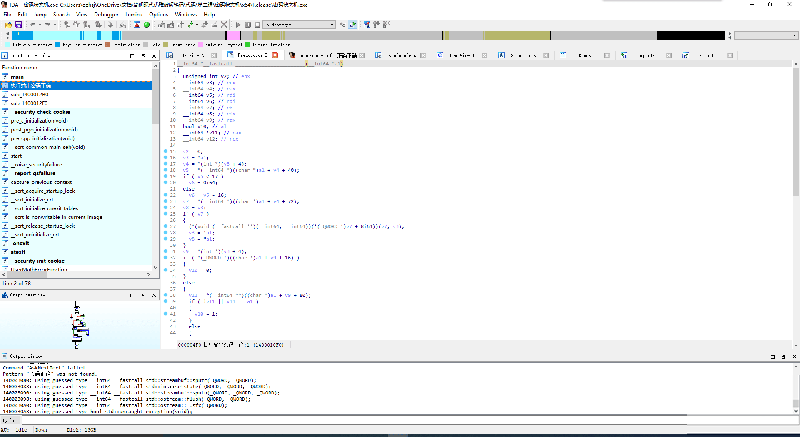
再次选中这个函数的名字,按X键,即可弹出这个函数所有被调用的位置。
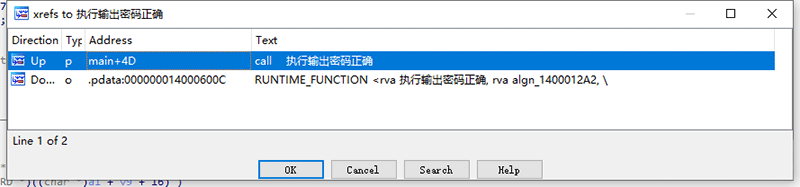
顺着call往前找,双击即可,会发现我们来到了main函数。看来在反编译器中不太建议使用中文重命名函数,但我们还是看到了曙光。
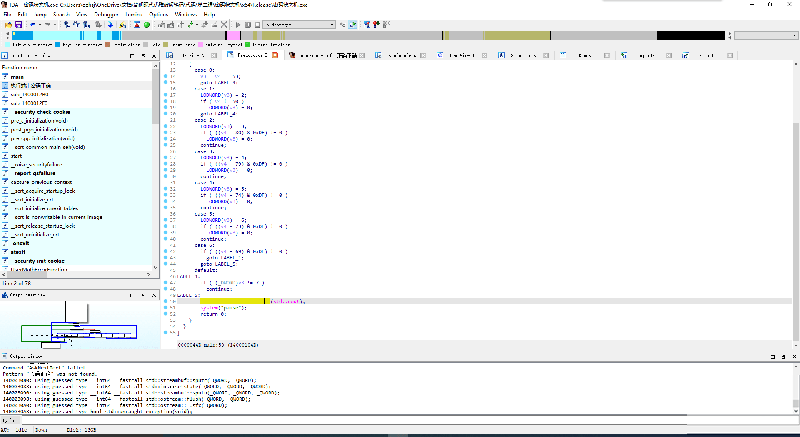
由此可知,只要让程序从开头就跳到LABEL_5,就可以绕过密码验证,这是暴力破解的思路,我们就这样尝试一下。
Switch-case结构跑到main函数里来,并且状态机对象不知所踪,这是因为VC的编译器非常强悍,自由度也很高。你通过C++代码完美表达了你的思想,但编译器理解了你的思想后,选择了一个最适合机器执行的方式来编写机器指令的程序,并没有严格按照你的思路去转换。这就是编译器优化的可怕之处,我们平时碰到的原生代码大多数都是经过编译器优化的,但是不同的编译器功力会有深有浅,像微软C++编译器这样功力深厚的其实并不多见(因为它不仅有编译优化,还有链接优化和全程序优化,而其他编译器限于与链接器合作不足无法进行链接优化和全程序优化)。所以我们最终需要理解的代码可能和作者原来写的完全不相干,但是他们都体现了相同的逻辑。
暴力破解方案
回到IDA-View,我们可以看到main函数运行的框图。在框图最下面,我们可以看到我们想要跳转到的位置,LABEL_5的实际地址,我们需要想办法让main函数直接跳到这里。
有许多不负责任的教程教你直接动态调试,寻找关键跳,然后直接把跳转给取消,或者让它跳到别的地方。原理是没有太大问题的,但是执行起来很不安全,在你对于一个程序没有宏观了解,胸中无成竹的时候,盲目改跳转很容易让程序栈变得不平衡,从而使得程序易于崩溃。
为了确保我们修改后的程序执行时不会崩溃,我们需要平衡程序的栈指针。先设置一下IDA,让IDA默认显示栈指针。点击Options -> General,在打开的窗口中的Disassembly选项卡中勾选Stack pointer.

点击OK后你会发现,程序指令代码的最左侧出现了一些000、008、028的绿色数字,这就是栈指针的位置。
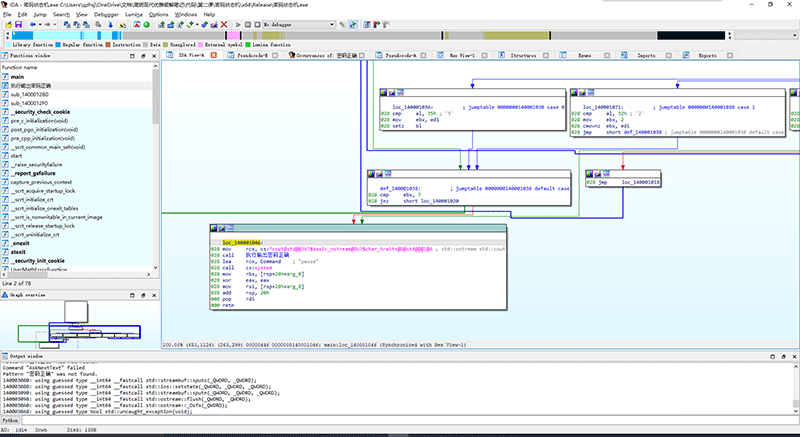
现在可以看到,我们要跳转的目标栈指针是028,所以我们一定要从同样是028的位置上跳过去。我们发现main函数的开头就有这样的位置,所以我们在这里物色好一句指令,把它修改成jmp到我们的目标位置。
我看上了第一个框中最后的一句028 lea rsi, cs:140000000h.根据第一节课提到的方法,我们可以把这句改掉,改成jmp loc_140001046.

可以看到,IDA的框图几乎立刻改变了连线,我们根据第一节课提到的方法保存修改后的程序,可以发现程序已经爆破成功。
获知真正的密码
只会暴力破解有时确实足够了,但作为一个逆向工程师这并不代表任何水平,如果你能通过查看程序代码的方式获知密码,不修改程序,只是知道密码是多少,你才能够被称为一个有能力的逆向工程师。
显然,main函数中while里面的内容就是编译完成后的算法代码,很容易发现v4是用户每次键盘输入的字符。经过人脑运行,发现这个代码里还被编译出了位运算这种骚操作,一步一步走下去的话,v4需要先后等于:53、50、80或112、79或111、74或106、73或105、69或101.查ASCII码表可知,密码为52pojie不区分大小写。
到了这部分,就只能自己用脑子跟算法了,没有工具可以辅助,但好在一般需要看这种东西的时候也不是太难,难的算法有另外的分析方法。这个我也没有学习得炉火纯青,还是留待后面的日子里在笔记中慢慢整理完善吧。
尾记
其实我也是第一次如此细致地对比一个非常简单的程序的Debug和Release版本的区别,我发现这样看来,编译器这一层足够把人类的思维和最终运行的代码分隔开了。经过编译器优化的代码是精巧的,不仅完美适合机器运行,还能精确满足编写者的需求。在此向微软的编译器团队致以最崇高的敬意!
学会了如何查找关键信息,并一点一点抽丝剥茧理清程序逻辑,并找到关键修改点或者理解整个算法,接下来我们就要学习如何在没有任何信息可查的情况下尽快入手干活了。这将是下一期的内容,下一期将使用我曾经编写过的一个现成的CrackMe,我将不需要再啰嗦正向开发的内容。
评论(0)